Understanding World Models: AI's Internal Map of Reality


World Models (WMs) are a fundamental concept in artificial intelligence (AI) and are seen by some top researchers as the key to making progress towards Artificial General Intelligence (AGI) and ultimately Artificial Super Intelligence (ASI). Think of them as internal maps of reality that an AI creates for itself to understand the world around it. These maps allow the AI to simulate and predict what might happen next based on what it sees and does. They do this by understanding basic rules about the world, like physics, cause-and-effect, and how objects are arranged in a space.
The concept draws inspiration from how humans subconsciously build mental models to anticipate outcomes. For example, a baseball player can predict a pitch's trajectory without having to consciously run through all the physics calculations. In the same way, world models help an AI handle uncertainty, forecast events, and make better decisions by rehearsing scenarios in a safe, simulated space rather than relying only on real-world trial and error.
The idea of World Models was introduced in a 2018 paper by David Ha and Jurgen Schmidhuber. Their framework had three key parts:
- A vision model to process complex information like video
- A memory model to predict what might happen next
- A controller model to decide on actions.
In practice, a WM usually has an encoder to turn inputs (like images and actions) into a simple representation, and a predictor to forecast future events. An LLM's structure is a bit different: it uses a tokenizer to process text, and its core architecture (which relies heavily on an attention mechanism) works to predict the most likely next word in a sentence, not the next state of an entire environment.
The Debate: Does AI Actually Understand the World?
A major debate in AI right now is whether today's models actually build these internal maps of reality or if they are just incredibly good at predicting the next word or pixel. This question of "prediction versus understanding" cuts to the heart of what we want these systems to achieve.
A recently published study from Harvard and MIT put this to the test. Researchers trained an AI on data from millions of simulated solar systems to see if it could learn the underlying mechanics of gravity. The results were telling. The model became excellent at predicting a planet's future trajectory, but when researchers inspected its internal logic, they found its calculation of the gravitational force was wildly inaccurate. Essentially, the AI learned a clever shortcut to guess what would happen next without grasping the fundamental law of gravity explaining why.
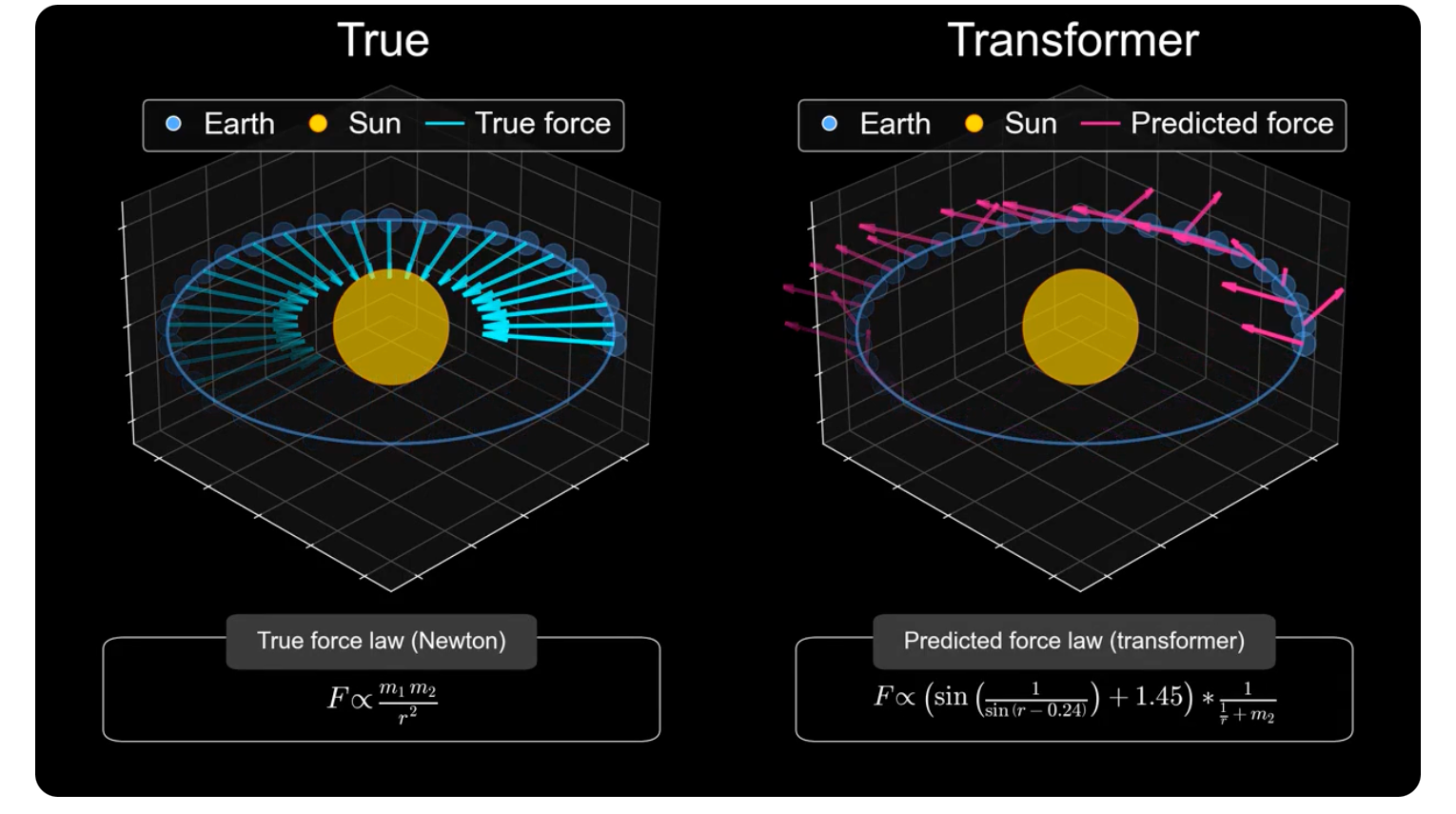
Even more revealing, when tested on different solar systems (distinct samples from outside its training data), the model invented different, inconsistent force laws for each one. It wasn’t even coherent in its own flawed logic, let alone coherent with the physics of our universe.
The goal of the test was to distinguish between a model that's just a sophisticated pattern-matcher and one that has developed a genuine, flexible internal map of cause and effect.
This study suggests that simply training a model to predict the next step doesn't guarantee it has built a true, flexible world model. However, critics of the study argue that the AI used was far smaller than today's biggest models. They point to other research showing that larger models do seem to develop these internal maps as they are trained. The verdict is still out, but it’s clear that building a robust world model isn’t guaranteed just by making an AI a better predictor.
Why World Models Matter for AGI
To graduate from being a text predictor to achieving true Artificial General Intelligence (AGI), the AI models need to understand the world more like a human. Many of the world's top researchers believe WMs are the key to this leap because they help instill two critical abilities that current systems lack: intuitive common sense and a grounded understanding of physical reality.
Yann LeCun, Meta's chief AI scientist, argues that common sense is the biggest missing piece in AI today.
This isn't about knowing facts; it's the intuitive grasp of cause-and-effect we use every second of the day—for example, knowing a glass will likely shatter if you drop it on a hard floor.
Current AI models that only learn from text struggle with this because of how they fundamentally see the world: through text. A world model provides that connection. By creating an internal simulation of how things work, the WFM can learn the basic "rules" of reality, allowing it to reason and plan based on a foundation of common sense.
Similarly, Fei-Fei Li, a leading figure in the field and commonly referred to as the "Godmother of AI", emphasizes that intelligence is deeply tied to our physical environment.
Fei-Fei explains that language is like a summary of the real world—and in any summary, details get left out. For example, reading a million descriptions of 'gravity' isn't the same as learning how it works by watching objects fall
World models, especially those trained on visual data like video, can directly learn the physical dynamics in the real world. This allows an AI to grasp concepts that are fundamental to our intelligence but are missed when using text alone, such as spatial relationships, object permanence, and physical interaction.
Video Credit: JD Fetterly
In short, world models matter for AGI because they aim to move AI beyond simply manipulating language and towards a genuine, predictive understanding of the world we all live in.
What Are the Challenges in Building WMs?
Despite their immense potential, building effective world models and getting them ready for real-world products is a monumental task. Developers face several key obstacles that separate today's research from tomorrow's applications.
- Discovering the Scaling Laws for Reality For LLMs, researchers defined the "AI Law of Scaling"—predictable improvements that come from making the models and datasets bigger. For WMs there is no blueprint, the core research challenge is discovering how to scale them effectively. It's not just about adding more data; it's about figuring out the right kind of data (video, physical interaction, text, geospatial) and the right model architectures that allow a true understanding of physics to emerge. Researchers are still exploring the fundamental relationship between model size, data complexity, and the leap to genuine comprehension.
- Ensuring Factual and Physical Grounding A major research obstacle is ensuring the model's internal simulation remains strictly tied to the rules of reality. Like other AIs, WMs can "hallucinate," but the stakes are higher. The challenge isn't just preventing errors, but building models that are inherently grounded in physics. For example, an LLM model might generate a video of a ball falling up or a glass bouncing without shattering.
- Learning from Sparse and Multimodal Data The physical world delivers information through many channels at the same time—sight, sound, touch. A key research problem is how to train a model to learn from messy, multimodal data in an efficient manner. Unlike the vast and well-organized text data on the internet (Thank you Google for 25 years of indexing!), high-quality data capturing physical interactions is relatively scarce. Researchers need to figure out how to build models that can form a coherent understanding of an event, like a tree falling, by integrating the visual information (the tree tipping over), the audio (the cracking sound), and the physical outcome (the crash) from a limited set of examples.
Applications and Future Potential
he potential of world models extends far beyond our screens, promising to bridge the gap between digital intelligence and the physical world. Instead of just generating content, they can simulate reality, unlocking new frontiers in robotics, science, and creativity.
Smarter, Safer Robotics Imagine a home assistance robot that doesn't just see a glass of water on a table, but understands that spilling it will make the floor slippery and that it must be handled delicately. Or a self-driving car that doesn't just detect a ball rolling into the street, but anticipates that a child might follow it. By rehearsing millions of scenarios in a physically-grounded internal simulation, robots and autonomous systems can move from simply following commands to exercising true judgment. This makes AI in the physical world safer, more adaptable, and vastly more capable.
The End of the Uncanny Valley Generative video is impressive, but it's often plagued by an "uncanny valley" of bizarre physical errors—a person's hand passing through a solid object, or a glass bouncing when it should shatter. A true world model, like the engine behind systems like OpenAI's Sora, learns an intuitive model of physics from video data. This allows it to generate content that isn't just plausible, but physically coherent. This is the key to creating infinite, interactive worlds for gaming, virtual reality training, and architectural visualization that feel truly real because they are governed by a learned sense of physics.
Accelerating Scientific Discovery What if a biologist could simulate how a new drug will interact with a cell, or an engineer could model how a new material will behave under extreme stress—all within an AI-driven simulation? World models hold the potential to create "digital twins" of complex real-world systems. By understanding the underlying physical and causal rules, they could allow researchers to test hypotheses at a speed and scale impossible today, dramatically accelerating innovation in fields from drug discovery and materials science to climate modeling.
Conclusion
The rise of Large Language Models has demonstrated an incredible mastery of the symbolic world of text, but language is ultimately a summary of reality, not reality itself. To graduate from manipulating symbols to truly interacting with our world, intelligence needs a foundation in the physical rules that govern it. This is where world models play a crucial role: to provide the grounded, intuitive "common sense" that text alone cannot.
The future of advanced AI, therefore, is likely not a choice between these two architectures, but a convergence of them. Imagine an AI that combines an LLM's sophisticated linguistic reasoning with a WFM's intuitive grasp of physics. A system that could understand a spoken command—"carefully place that antique vase on the wobbly table"—and execute it with a nuanced understanding of the physical properties involved: fragility, weight, momentum, and stability.
While the path to building robust world models is still unfolding, their development isn't a departure from the progress in language, but a necessary and powerful complement to it. The ultimate pursuit is a more complete intelligence, one that can both speak our language and understand our world, finally bridging the long-standing gap between the digital and the physical.
Written by JD Fetterly - Data PM @ Apple, Founder of ChatBotLabs.io, creator of GenerativeAIexplained.com, Technology Writer and AI Enthusiast.
All opinions are my own and do not reflect those of Apple.